Harnessing the Power of Convolutional Neural Networks for Text Classification
- edgestore41
- Jan 28, 2025
- 6 min read


In the ever-evolving realm of Natural Language Processing (NLP), Convolutional Neural Networks (ConvNets) have risen to prominence for their groundbreaking achievements in various NLP tasks. One particularly compelling application is sentence classification, wherein short phrases consisting of approximately 20 to 50 tokens are categorized into predefined classes. This article elucidates the utilization of ConvNets for short-sentence classification and provides insights into their seamless implementation using the Keras framework.
The Essence of Convolutional Neural Networks
Originally developed within the image processing domain, ConvNets achieved remarkable success in identifying objects belonging to predefined categories, such as recognizing cats, bicycles, and more. A Convolutional Neural Network primarily involves two core operations, akin to feature extraction mechanisms: convolution and pooling.
Convolutions: Extracting Features
Imagine an input image presented as a matrix, where each entry represents a pixel with a brightness intensity ranging from 0 to 255. To grasp the concept of convolution, visualize placing a convolution filter or kernel atop the image, aligning it with the upper-left corner of the image. The filter's values are multiplied with the corresponding pixel values in the image, and the resulting values are summed to generate a scalar placed in the result matrix.
The kernel then shifts to the right by a specified stride length, and the process repeats. The result matrix gradually fills up as the convolution proceeds. This iterative process is conducted row by row and column by column, covering the entire input image. The outcome is termed a convoluted feature or input feature map. Multiple convolution kernels can be employed concurrently, producing distinct outputs for each kernel.
Pooling: Extracting Representations
Subsequent to convolution, the pooling or downsampling layer comes into play. This layer involves applying an operation across regions or patches of the input feature map, aggregating representative values for each analyzed region. Common pooling methods encompass max-pooling and average-pooling. Max-pooling identifies the maximum value within each region, while average-pooling computes the average value. This pooling operation significantly reduces the output size while retaining essential information.
Adapting Convolutional Neural Networks for NLP
In the context of Natural Language Processing, where text rather than images is the focus, ConvNets undergo an architectural transformation to facilitate 1D convolutional and pooling operations. A notable application of ConvNets in NLP is sentence classification, where sentences are categorized into predefined classes by considering n-grams, i.e., words, sequences of words, characters, or sequences of characters.
1D Convolutions over Text
When processing text, a sequence of words is represented as a 1-dimensional array. In this scenario, ConvNets employ 1D convolutional-and-pooling operations. Given a sequence of words and their associated embedding vectors, a 1D convolution involves sliding a window of a certain width over the sentence and applying a convolution filter or kernel to each window. The result is obtained by computing the dot-product between the concatenated embedding vectors within the window and a weight vector, followed by a non-linear activation function.
Channels in Text Processing
Channels, a concept from image processing, can also be applied to text analysis. In text processing, a channel might represent a sequence of words, another channel could embody the sequence of corresponding POS tags, and yet another might signify the shape of the words. By applying convolution over each channel, distinct vectors are generated. These channels' outputs can be combined through summation or concatenation, enhancing the network's ability to capture diverse linguistic features.
Pooling for Feature Combination
Pooling further consolidates the vectors produced by various convolution windows into a unified multidimensional vector. The pooling operation computes either the maximum or average value from each convolution result vector. This vector then advances through the network, often reaching a fully connected layer to facilitate prediction.
Convolutional Neural Networks in Sentence Classification
To exemplify ConvNet usage, an experiment was conducted based on Yoon Kim's paper. Four ConvNet models were implemented and assessed for sentence classification:
CNN-rand: All words are initially randomized and then updated during training.
CNN-static: Pre-trained vectors are utilized for all words, with only non-word parameters being learned.
CNN-non-static: Similar to CNN-static, but word vectors are fine-tuned.
CNN-multichannel: This model integrates two sets of word vectors, treating each set as a separate channel and applying filters accordingly.
Experimentation and Outcomes
import os import numpy as np from gensim.models import Word2Vec from gensim.utils import simple_preprocess from gensim.models.keyedvectors import KeyedVectors from keras.activations import relu from keras.models import Sequential, Model from keras.layers import Input, Dense, Embedding, Flatten, Conv1D, MaxPooling1D from keras.layers import Dropout, concatenate from keras.utils.vis_utils import model_to_dot from sklearn.metrics import classification_report from IPython.display import SVG |
Utils functions
def load_fasttext_embeddings(): glove_dir = '/Users/dsbatista/resources/glove.6B' embeddings_index = {} f = open(os.path.join(glove_dir, 'glove.6B.100d.txt')) for line in f: values = line.split() word = values[0] coefs = np.asarray(values[1:], dtype='float32') embeddings_index[word] = coefs f.close() print('Found %s word vectors.' % len(embeddings_index)) return embeddings_index def create_embeddings_matrix(embeddings_index, vocabulary, embedding_dim=100): embeddings_matrix = np.random.rand(len(vocabulary)+1, embedding_dim) for i, word in enumerate(vocabulary): embedding_vector = embeddings_index.get(word) if embedding_vector is not None: embeddings_matrix[i] = embedding_vector print('Matrix shape: {}'.format(embeddings_matrix.shape)) return embeddings_matrix def get_embeddings_layer(embeddings_matrix, name, max_len, trainable=False): embedding_layer = Embedding( input_dim=embeddings_matrix.shape[0], output_dim=embeddings_matrix.shape[1], input_length=max_len, weights=[embeddings_matrix], trainable=trainable, name=name) return embedding_layer def get_conv_pool(x_input, max_len, sufix, n_grams=[3,4,5], feature_maps=100): branches = [] for n in n_grams: branch = Conv1D(filters=feature_maps, kernel_size=n, activation=relu, name='Conv_'+sufix+'_'+str(n))(x_input) branch = MaxPooling1D(pool_size=max_len-n+1, strides=None, padding='valid', name='MaxPooling_'+sufix+'_'+str(n))(branch) branch = Flatten(name='Flatten_'+sufix+'_'+str(n))(branch) branches.append(branch) return branches |
Convolutional Neural Networks for Sentence Classification
1 Hyperparameters and Training
For all datasets we use:
rectified linear units;
filterwindows (h) of 3, 4, 5 with 100 feature maps each;
dropout rate (p) of 0.5;
l2 constraint (s) of 3;
mini-batch size of 50;
These values were chosen via a grid search on the SST-2 dev set.
We do not otherwise perform any dataset specific tuning other than early stopping on dev sets. For datasets without a standard dev set we randomly select 10% of the training data as the dev set.
Training is done through stochastic gradient descent over shuffled mini-batches with the Adadelta update rule (Zeiler, 2012).
2 Pre-trained Word Vectors
We use the publicly available:
word2vec vectors that were trained on 100 billion words from Google News.
Words not present in the set of pre-trained words are initialized randomly.
3 Models Variations
1) CNN-rand: all words are randomly initialized and then modified during training
def get_cnn_rand(embedding_dim=100, vocab_size=1000, max_len=50): # create the embedding layer embedding_matrix = np.random.rand(vocab_size, embedding_dim) embedding_layer = get_embeddings_layer(embedding_matrix, 'embedding_layer_dynamic', max_len, trainable=True) # connect the input with the embedding layer i = Input(shape=(max_len,), dtype='int32', name='main_input') x = embedding_layer(i) # generate several branches in the network, each for a different convolution+pooling operation, # and concatenate the result of each branch into a single vector branches = get_conv_pool(x, max_len, 'dynamic') z = concatenate(branches, axis=-1) z = Dropout(0.5)(z) # pass the concatenated vector to the predition layer o = Dense(1, activation='sigmoid', name='output')(z) model = Model(inputs=i, outputs=o) model.compile(loss={'output': 'binary_crossentropy'}, optimizer='adam') return model model_1 = get_cnn_rand() SVG(model_to_dot(model_1, show_layer_names=True, show_shapes=True).create(prog='dot', format='svg')) |

2) CNN-static: pre-trained vectors with all the words— including the unknown ones that are randomly initialized—kept static and only the other parameters of the model are learned
embeddings_index = load_fasttext_embeddings() Found 400000 word vectors. vocabulary = embeddings_index.keys() # replace this by the vocabulary of the dataset you want to train embeddings_matrix = create_embeddings_matrix(embeddings_index, vocabulary, 100) Matrix shape: (400001, 100) embedding_layer = get_embeddings_layer(embeddings_matrix, 'embedding_layer_static', 55, trainable=False) def get_cnn_pre_trained_embeddings(embedding_layer, max_len): # connect the input with the embedding layer i = Input(shape=(max_len,), dtype='int32', name='main_input') x = embedding_layer(i) # generate several branches in the network, each for a different convolution+pooling operation, # and concatenate the result of each branch into a single vector branches = get_conv_pool(x, max_len, 'static') z = concatenate(branches, axis=-1) # pass the concatenated vector to the predition layer o = Dense(1, activation='sigmoid', name='output')(z) model = Model(inputs=i, outputs=o) model.compile(loss={'output': 'binary_crossentropy'}, optimizer='adam') return model model = get_cnn_pre_trained_embeddings(embedding_layer, 55) SVG(model_to_dot(model, show_layer_names=True, show_shapes=True).create(prog='dot', format='svg')) |
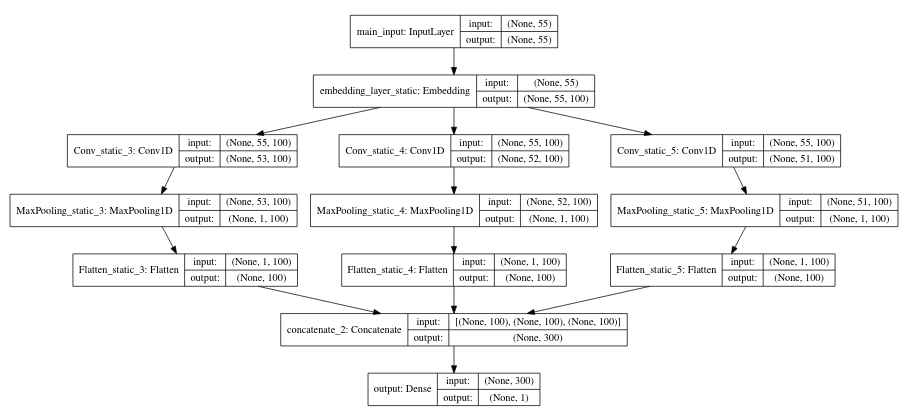
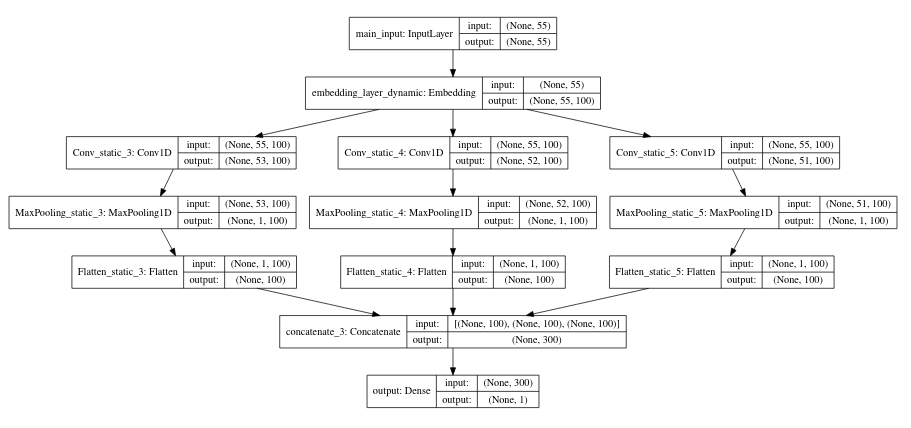
3) Same as above but word vectors are fine-tuned
embedding_layer = get_embeddings_layer(embeddings_matrix, 'embedding_layer_dynamic', 55, trainable=True) model = get_cnn_pre_trained_embeddings(embedding_layer, 55) SVG(model_to_dot(model, show_layer_names=True, show_shapes=True).create(prog='dot', format='svg')) |
4) CNN-multichannel: A model with two sets of word vectors. Each set of vectors is treated as a channel and each filter is applied
embedding_layer_channel_1 = get_embeddings_layer(embeddings_matrix, 'embedding_layer_dynamic', 55, trainable=True) embedding_layer_channel_2 = get_embeddings_layer(embeddings_matrix, 'embedding_layer_static', 55, trainable=False) def get_cnn_multichannel(embedding_layer_channel_1, embedding_layer_channel_2, max_len): # dynamic channel input_dynamic = Input(shape=(max_len,), dtype='int32', name='input_dynamic') x = embedding_layer_channel_1(input_dynamic) branches_dynamic = get_conv_pool(x, max_len, 'static') z_dynamic = concatenate(branches_dynamic, axis=-1) # static channel input_static = Input(shape=(max_len,), dtype='int32', name='input_static') x = embedding_layer_channel_2(input_static) branches_static = get_conv_pool(x, max_len, 'dynamic') z_static = concatenate(branches_static, axis=-1) # concatenate both models and pass to classification layer z = concatenate([z_static,z_dynamic], axis=-1) # pass the concatenated vector to the predition layer o = Dense(6, activation='sigmoid', name='output')(z) model = Model(inputs=[input_static, input_dynamic], outputs=o) model.compile(loss={'output': 'binary_crossentropy'}, optimizer='adam') return model model = get_cnn_multichannel(embedding_layer_channel_1, embedding_layer_channel_2, 55) SVG(model_to_dot(model, show_layer_names=True, show_shapes=True).create(prog='dot', format='svg')) |

The implemented models were applied to datasets similar to those in Kim's paper. However, exact replication of results was not possible due to differences in frameworks, data preprocessing, and tokenization. Additionally, focusing solely on accuracy as an evaluation metric may not be ideal when classes are unevenly distributed.
Benefits of Using CNNs for Text Classification
Automatic Feature Extraction: CNNs automatically learn relevant features from the text, reducing the need for manual feature engineering.
Hierarchical Feature Learning: CNNs can capture hierarchical relationships in text data, from character-level patterns to higher-level semantic features.
Parallel Processing: CNNs can process text data in parallel, making them computationally efficient.
Transfer Learning: Pretrained word embeddings (e.g., Word2Vec, GloVe) can be used to improve model performance even with limited data.
Wrapping Up
Convolutional Neural Networks stand as pivotal feature-extraction tools, forming the foundation of broader networks. They need to collaborate with a classification layer for meaningful outcomes. The essence of a ConvNet's role is to identify vital local patterns within a structure, aiding in prediction tasks. In Natural Language Processing, ConvNets excel in uncovering predictive n-grams without necessitating pre-defined embeddings for each potential n-gram. As the technology landscape continues to evolve, ConvNets wield immense potential in revolutionizing the way we process and understand textual data.



Comments